2/22(月)~2/28(日)の一週間の学習の振り返りをざっくり。
今週の目標&結果
| 今週の目標 | 結果 |
|---|---|
| TwitterのDB設計をどうやって行ったかまとめる | 日報に詳細書いてあるので、やめた |
| DB設計:他の受講生の提出物をチェック | ◯ |
| 自己参照/自己結合の理解 | ◯ |
| 【ブログ】DB設計で学んだこと&詰まった点 | ◯ |
| 【ブログ】web技術の基本で学んだこと | ◯ |
| 【ブログ】webを支える技術で学んだこと | ◯ |
| 【ブログ】URL設計について学んだこと | ◯ |
| 【ブログ】Gitで課題提出するまでの手順 | ◯ |
| 【ブログ】TeamGeekを輪読会の感想 | ✕ 着手もできず |
| 2月の振り返り&計画の見直し | ◯ |
| (できれば)Railsの教科書の6~8章(最後) | △ 6と8は完了/ 残り7章 |
| (できれば)book_appをリモートリポジトリのmainブランチにpushする | ✕ |
今週の学習時間
プラクティス外の学習・勉強会への参加は含めない。
| 日付 | 目標 | 実際 |
|---|---|---|
| 2/22(月) | 2:00 | 0:00 |
| 2/23(火)祝日 | 6:00 | 0:45 |
| 2/24(水) | 2:00 | 2:00 |
| 2/25(木)休み | 6:00 | 4:15 |
| 2/26(金) | 2:00 | 0:00 |
| 2/27(土) | 6:00 | 7:30 |
| 2/28(日) | 6:00 | 8:15 |
| 合計 | 30:00 | 22:45 |
今週やったこと
2/22(月
やったこと
- 学習せず。
考えたこと
- 入浴した後、自室で学習していたのだが、眠すぎて週報を書くことすらできなかった。お風呂に入ると体が一気に睡眠モードになってしまう😴
- 復習が疎かになっているので、Railsに本格的に入る前に、今週はDB設計,RESTの復習に注力する予定。
2/23(火)祝日
やったこと
- 土曜の日報提出
- 週報ブログを書いた:週報 2/15(月)~2/21(日)
考えたこと
- 週報を書いた後、復習をかねてブログを書こうとしたら、少し疲れていてなかなか集中できず、せっかくコワーキングスペースに行ったのに帰ってしまった。
いつもはコワーキングスペースに行くとスッと集中モードに入れるので、うまく睡眠が取れなかったのかなと思った。
2/24(水)
やったこと
- Railsの教科書(5~6,8章)
考えたこと
- 5-6章,8章を読み終わった!残るは7章!
- Ruby3.0.0でawesome_printが使えない問題は、バージョン1.9.0で解決されている。時間があるときに試す。
- bundlerの仕組みがよく分からずモヤモヤしていたが、「Bundlerは、GemfileとGemfile.lockで互換性の管理をしつつ、bundle updateで新しいバージョンもインストールして使えるから、便利だよ!」ということが分かった💡Ruby超入門10-1にも記述があるので、読み返す。
2/25(木)
やったこと
- 復習をかねてブログ記事を2本書いた
考えたこと
- DB設計は、色んなところで理解につまづき、世界観?を理解するのが難しかったので、これから学ぶ方の助けになればいいなという気持ちで書いた。
- Gitの記事は、フィヨルド生で参考になったと仰ってくださる方がいて嬉しかった!
2/26(金)
やったこと
- 学習せず。
考えたこと
- 早起きに失敗して出勤前に学習できず&仕事後疲れて学習できなかった。
2/27(土)
やったこと
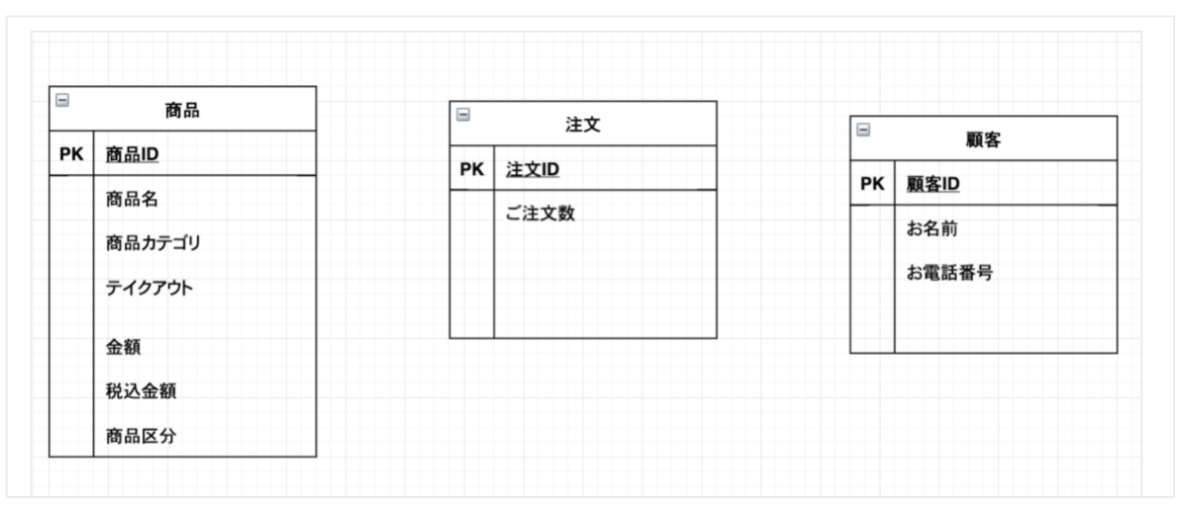
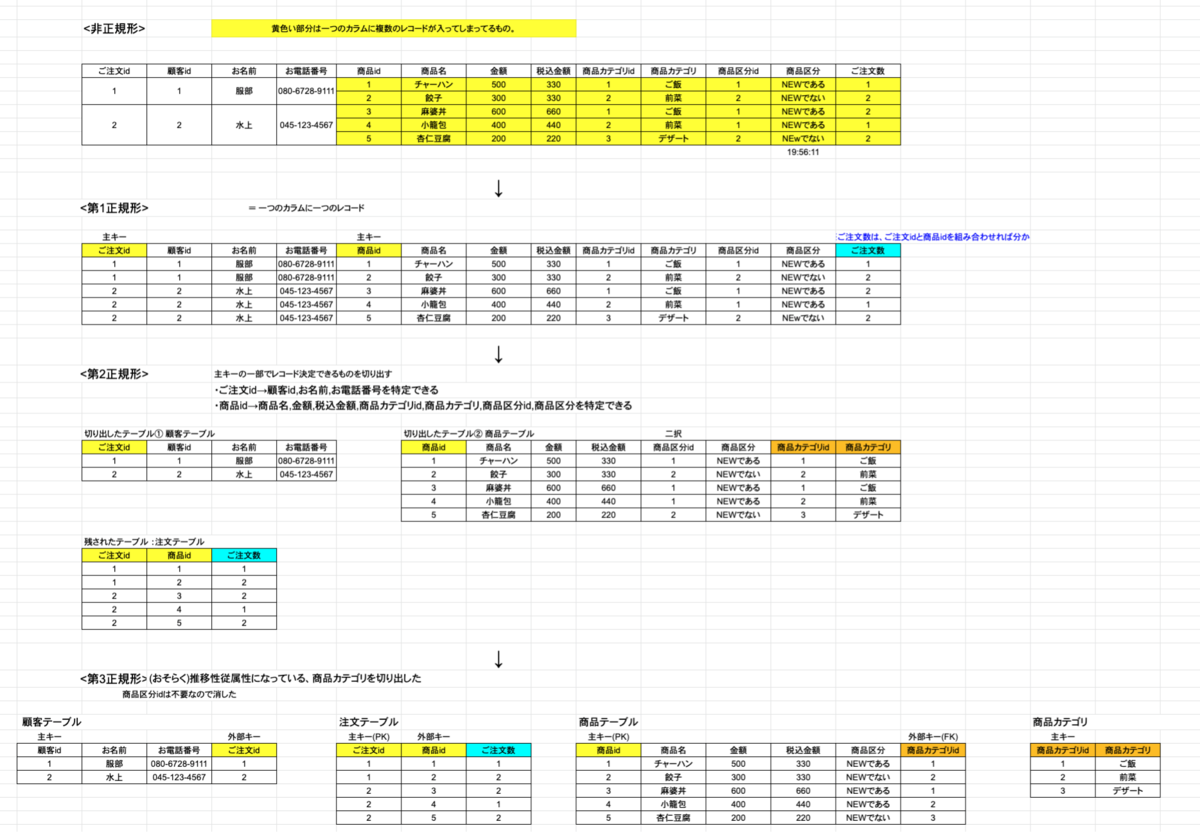
- DB設計:他の方の提出物を見る
- ブログ記事を書いた:『Web技術の基本』を読んで学んだこと
考えたこと
- ずっと後回しにしていた、去年秋に読み終わった『Web技術の基本』を読んで学んだこと・疑問に思って調べたこと・感想を書けた。
- ブログが思ったより、書くのに時間がかかった💦久々に本の内容を復習して、それを自分なりに言葉で説明してまとめたので、良い復習になった。
- 伊藤さんの記事:ブログに技術書の内容を丸写しする問題点と、オリジナルなコンテンツを書くためのアイデアを参考にしながら、記事の内容が無断転載にならないように、気をつけて書いたが、大丈夫か少し心配😅もしご指摘があったらすぐに修正or削除するつもり。
2/28(日)
やったこと
- ブログ記事を2本書いた
考えたこと
- ずっと書こうと思って後回しにしていた記事を2本も書けた!
今週の振り返り
✅ できたこと/できるようになったこと
- 今週はブログでたくさんアウトプットできた!週報をのぞいて記事5本書いた。がんばった〜💪
- 気づけば今年から始めた週報を2ヶ月連続で書けている。書かないと気持ち悪くなるくらい習慣化できている✨
- 最近休みの日は無理やり早起きせず、ぐっすり眠ることを重視している。アラームも休みの日はつけないことにした。
無理やり早起きしても後でエネルギー切れを起こしてしまうので、8時台まで寝るのは許容範囲にしている。
✅ "こうしたらもっと良かった"と思うこと
- 火曜の祝日にもう少し学習できたらよかったな〜と思う。でも、毎日元気全開で学習するのは難しいので、反省はしても責めないようにする。 やる気と健康にはムラがあるもの!
来週の目標
合計23:00分