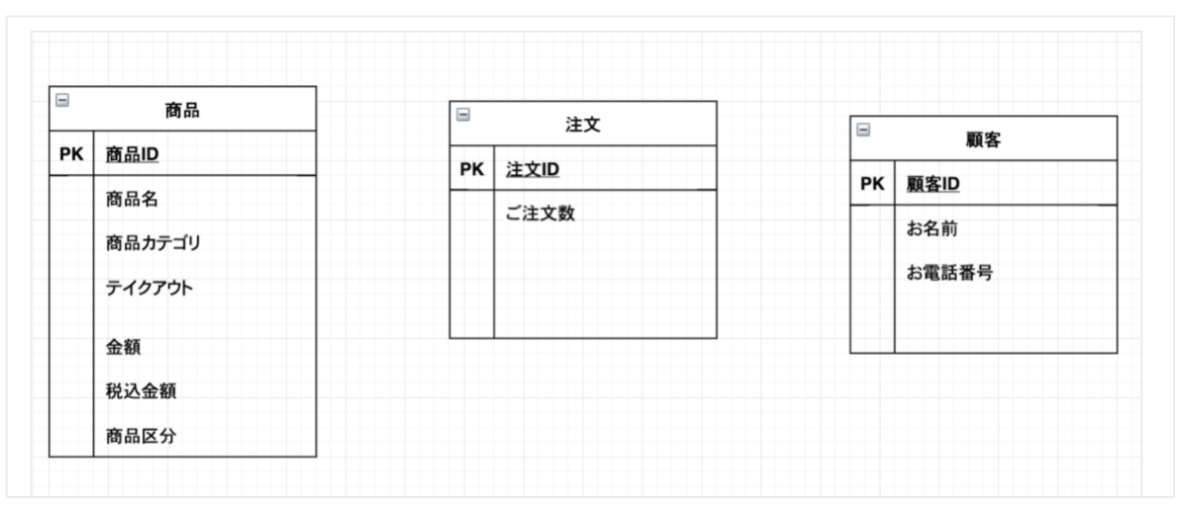
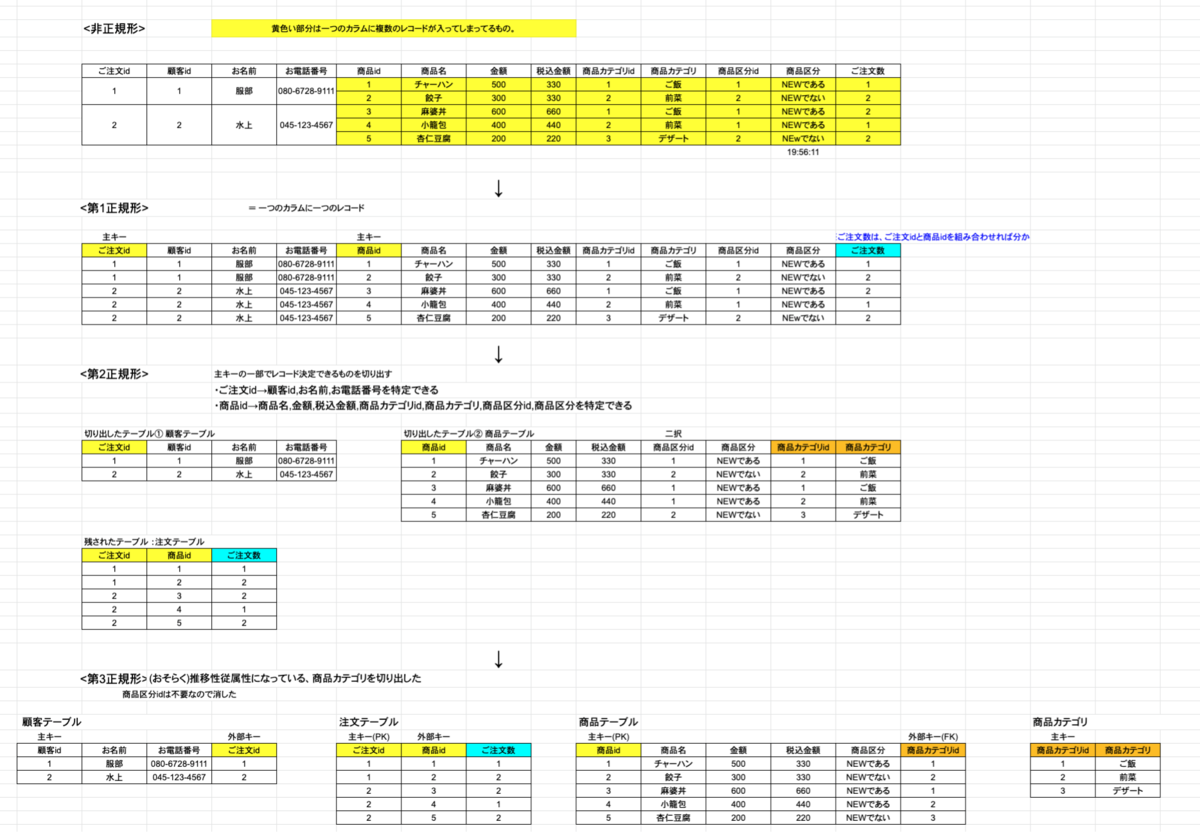
フィヨルドブートキャンプで、「Webを支える技術 -HTTP、URI、HTML、そしてREST」(以下、「Webを支える技術」)を読むという課題があったが、必要な前提知識に不足があり、理解が難しかった。
この本が難しい場合は『イラスト図解式 この一冊で全部わかるWeb技術の基本』(以下、「Web技術の基本」)が、イラストが多く最初にイメージを掴むのに最適とアドバイスをいただいたので、そちらを先に読むことにした。
読み終わったので、読んだ中で学んだこと・調べたこと、感想を書いた。
<<無断転載にならないよう気をつけて書いたつもりですが、もしご指摘等ありましたら修正あるいは削除させていただくつもりです>>
- 本の構成
- ch1. Web技術とは
- ch2. Webとネットワーク技術
- ch3. HTTPでやりとりする仕組み
- ch4. Webのさまざまなデータ形式
- ch5. Webアプリケーションの基本
- ch6. Webのセキュリティと認証
- ch7. Webシステムの構築と運用
- 全体の感想
本の構成
ch1. Web技術とは
ch2. Webとネットワーク技術
ch3. HTTPでやりとりする仕組み
ch4. Webのさまざまなデータ形式
ch5. Webアプリケーションの基本
ch6. Webのセキュリティと認証
ch7. Webシステムの構築と運用
ch1. Web技術とは
学んだこと
- HTMLを人が見やすいように変換しているのは、Webサーバーではなく、Webブラウザ。
Webページが表示される流れ
- 一度のコンテンツ転送で送られてくるファイルは1つ。
- 画像など他のファイルがそのコンテンツに埋め込まれていて、転送が必要になったときはもう一度Webサーバーに要求してファイルを取得する。
- 疑問:例えば、そのWebページに画像のファイルが10枚あったら、コンテンツに1回要求+画像ファイルの要求10回で11回要求するということか?
→以下の記事によれば、読み込むファイル1つにつき、HTTPリクエストが1回増えてしまうため、ファイル数が多いほど、表示までの時間が遅くなってしまう とあるので、やはり、ファイルの数の分リクエストとレスポンスが行われているようだ。
なぜ全てのサイトがSSL化しないのか?
調べたこと
- なぜ全てのサイトがSSL化しないのか疑問に思ったので調べた。
- 以下の記事を読んでみると、費用がかかったり設定が必要=コストがかかるからなのだろうか?
教わったこと
この疑問についてtechplay女子部のエンジニアの方が答えてくださったので、以下にまとめた。
- 2015年ぐらいは http のサイトも多かったと思う。
- 例えば企業のコーポレートサイトのようなものは、ユーザから入力を行わない画面(ただ会社概要などを表示しているだけの画面など)は http で、ユーザが入力を行う画面(問い合わせフォームなど)は https にリダイレクトさせる、みたいなことをよくやっているイメージだった。
- 問い合わせフォーム以外の画面は個人情報をサーバとやり取りしないので、保護されてなくても(=http でも)問題ないという認識。
- なぜ全てを https にせず一部だけリダイレクトする方法を取ってるのか?は推測だが、やはり https の方が暗号化してる分、通信量が増えるので、必要な部分だけ https にしようという感じだと思う。(当時はまだガラケーでも動作確認をしていたので、通信量は少ないに越したことがなかったのかもしれない)
- https があまり導入されなかった理由として料金の問題はあると思う。 当時、https を導入する場合は年間1万円はかかっていたと思う、無料のも聞いたことはなかった。
- しかし、https化を進めようという意識改革は、「全ページを https にしないと検索順位を下げる」方針にしたGoogle のおかげ。
- HTTPS をランキング シグナルに使用します
この宣言を皮切りに色んなところが https を進めるようになったんだと思う。
- HTTPS をランキング シグナルに使用します
- その後 ssl 証明書は無料で手に入るようになった。
- Let's Encrypt:無料ですぐに利用が可能なSSLサーバー証明書
- Let's Encryptが使われだしたのは、2016 年頃。
多くの Wordpress ユーザが使っていたレンタルサーバが無料 ssl を提供するようになり、httpsが当たり前になっていった。
- このように、今は無料でも ssl ができ、 Google の検索的にもhttpsにするべきという風潮がある。
→まとめると、今はSSL化することが当たり前で、していないサイトはほとんど無い。
CGIの仕組み
CGIは、Webサーバーがwebブラウザからの要求に応じてプログラムを起動するための仕組み。=クライアントからリクエストを受信すると、CGIによってプログラムが起動。
- 本を読んで、CGIがどのように動作しているのか仕組みが分からなかったので、調べたら、以下の記事の例えが分かりやすかった。
「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典 CGIとは
普通のホームページはスーパーで売っているお寿司と同じです。作り置きです。CGIでは、注文が入ってからホームページのファイルを作ります。
1.ホームページを見る人の注文をWebサーバ上にあるプログラムが受ける
2.注文を受けたプログラムが何かお仕事をする
3.注文を受けたプログラムがホームページのファイルを作って、ホームページを見る人に渡してあげる
の流れですね。
この流れを実現するためのあれやこれやがCGIです。
- 注意:CGIはWebサーバ上でプログラムを動かすための「仕組み」であって、プログラム自体を表す言葉ではない
クライアントサイド・スクリプト
- 主にJavaScriptが使われる。
- たしかに、グーグルクロム(=Webブラウザ)の設定でJavaScriptの設定を変更できた気がする。
- webブラウザ側=クライアント側で実行されるプログラムのこと。
- スクリプトとは:プログラムの種類の一つで、人間が読み書きしやすいプログラミング言語で書かれたプログラム(ソースコード)を即座に実行できるようなものを指す。
どんなプログラムかイメージしづらかったので、パスワードを登録する時に例えて考えた
- 新しいWebサービスを使うために新規ユーザー登録をするとき、大抵は「パスワードの文字数は8文字以上、大文字小文字を混ぜる」などの条件がある。
- クライアントがその条件を満たしてパスワードを設定できたかどうかは、誰が判断しているのか?
- Webは同時に何百人もの人がアクセスしてくるので、サーバにやらせるのは非効率。
- Google Chrome、Internet Explorerなどのブラウザが、送られたプログラムを解析し、ユーザが入力したデータなどをチェックしてからサーバへ送信している。
つまり、ユーザーがパスワードを条件通りに入力したかチェックしているのは、ブラウザ。 - このチェックしているプログラムが、クライアントサイド。スクリプト。
RESTful(RESTっぽい)とは
- RESTは、「これが REST な実装である」という厳密な定義があるわけではない。
- REST はアーキテクチャスタイル。スタイルなので、「REST っぽい」「REST っぽくない」といった語られ方をする。
考えたこと
- HTMLを人が見やすいように変換してくれているのが誰かは考えたことがなかった。なんとなくWebサーバーがやっていると思っていた。
- SSL化の背景についてここまで深く知ることは自力では不可能だったと思うので、教えてくださったエンジニアの方に深く感謝。今使われている技術がどういう背景で繁栄していったのかを知るのは楽しい。
ch2. Webとネットワーク技術
学んだこと
HTTP
- HTTPはハイパーテキスト=webコンテンツを送受信するためのプロトコル。
- TCP/IPはプロトコルの集まり=つまり、HTTPはTCP/IPの一部
- プロトコルは狼煙(のろし)。狼煙をあげる=「敵がきた!」という共通の取り決め。
TCP/IP
- TCP/IP(プロトコルの集まり)は、役割ごとに4つの階層に分かれる。レイヤー1~4。
クライアントとサーバーの両方にこの階層があり、同じ階層同士でプロトコルに従った処理をしている。 - 処理の流れ:レイヤー1から処理が始まって、レイヤー1→2→3→4とデータが渡されていく
- 階層を7つに分けた考え方もある=OSI参照モデル
IPアドレス/ドメイン
- ドメイン=IPアドレスの別名。
- IPアドレスはコンピューターが認識するために必要(ドメイン名だけではコンピューターは分からない)
- ドメインは人間にとって分かりやすいためのもの。IPアドレスは数字で表記されて読みにくい。
- ドメイン名⇔IPアドレスを名前変換する仕組みをDNSといい、DNSのサービスを提供するサーバーをDNSサーバーという。
DNSサーバー=ネームサーバー
- この紐付けを名前解決という。
考えたこと
- メンターさんに、TCP/IPの階層についてお聞きしたら、
- Webエンジニアとして働く上では、「アプリケーション層/HTTP」の部分を理解していればOK
- 他の階層については深く理解している必要はなく、階層になっているということが分かっていればOK
とのことだったので、今は、「階層に分かれている」ということを覚えておく。
ch3. HTTPでやりとりする仕組み
学んだこと
HTTPメッセージ
- HTTPメッセージ=HTTPリクエストとHTTPレスポンスの2種類
HTTPリクエスト/HTTPレスポンス
- HTTPリクエストの構成は、3つの構成でできている。
リクエスト行/(メッセージ)ヘッダー/メッセージボディ- リクエスト行:どうしたい
- ヘッダー:何を
- メッセージボディ:どんな方法で
- もし要求して応答されたwebページを解析したときに、画像のリンクがあったら、もう一度要求を送る。
 (HTTP入門 - とほほのWWW入門より引用)
(HTTP入門 - とほほのWWW入門より引用)
HTTPメソッド
- HTTPリクエストメソッド:簡単に言うと、WebブラウザからWebサーバに対しての命令(リクエスト)。
- リクエスト(命令・お願い)には色んな種類がある。
- Webサイト閲覧で主に使うのは
GETとPOST - 主に使われるメソッド
| メソッド | 動作 |
|---|---|
| GET | ページの取得を要求。WebブラウザからWebサーバに渡す値をURLの後ろにくっつけて送るやり方 |
| HEAD | ヘッダのみの要求 |
| POST | データをwebサーバーに送信 |
| PUT | webサーバーが保管してるコンテンツのアップロード(書き換え) |
| DELETE | 指定したデータを削除 |
| CONNECT | SSL |
HTTPバージョンの変遷
HTTP/1.0以前
- リクエストを送信するたびにコネクションを確立し、レスポンスでデータを送った時にコネクションを閉じていた。
- つまり、画像が埋め込まれていたらそのたびにリクエストを送る仕様になってるので、たくさん画像が埋め込まれているとリクエストの回数分だけコネクションの確立&閉じるをしなければならなかった。=効率が悪かった!
HTTP/1.1~
- コネクションを継続利用できる、「HTTPキープアライブ」ができた。
- HTTPパイプライン:複数のリクエスト&レスポンスを同時並行で行う。
HTTP/2
- HTTP/2はgoogleが提案したSPDYという通信の高速化を目的としたプロトコルが土台。
= HTTP/2の高速化を担う部分はほぼSPDYの機能を使っている。 - 2での改良点①
- 1.1のHTTPパイプラインは、HTTPリクエストの順番通りにレスポンスを返す。
- つまり、1つのレスポンスの処理が重いと遅くなってしまう(高速道路で渋滞が起こっているイメージ)という問題があった。
- この解決のために、コネクション上に仮想的な通信経路=ストリームを作った。
- 2での改良点②
- データのやりとりがテキスト形式→バイナリ形式に。前はテキスト形式だったので、バイナリ形式のデータを変換するのに負荷がかかっていた。
- バイナリ形式のデータとは:コンピュータが直接的に処理するために2進数で表現されたデータ
- そのため、ヘッダー情報を、2回目のやり取りからは追加情報(差分)だけ送るようにした。
- データのやりとりがテキスト形式→バイナリ形式に。前はテキスト形式だったので、バイナリ形式のデータを変換するのに負荷がかかっていた。
- 2での改良点③
HTTP/3
- 本には載っていなかったが、調べたら、HTTP/3がリリースされていた。
Cookie
- HTTPはステートレスなプロトコル。それをステートフルにしてくれるのがCookie。
例:ショッピングサイトのカートに入れた商品を次にログインしたときにも覚えてくれる。 - Cookieが使用される目的は大きく分けて次の2つ
- Webサイトでユーザー情報を保存し、利便性を向上する
- ユーザー情報を取得し、広告配信に利用する
- Webサイトでユーザー情報を保存し、利便性を向上する
- 仕組み
セッション
- セッション:クライアントがWebサーバーに接続してから切断されるまでの一連の行動を表す。
クライアントとサーバーで通信を行う場合、クライアントからサーバーへ接続した時点でセッションが始まり、サーバーから切断するとセッションが終了する。この一連の流れを管理することをセッション管理という。 - 例えばECサイトには、商品を探し、カートに入れ、購入するという一連の流れがある。このように同一利用者からのアクセスを関連性のある一連のアクセスとして扱いたい場合、Cookieを使ってセッション管理が行われる。
- セッションID:一連のやりとり(セッション)を識別するための一意の数字。銀行の受付番号と同じ。セッションIDをクッキーに格納してやりとりをすることによってステートフルな通信ができる。
- 各セッションにはIDが割り振られている。
- セッションのデータはサーバーに保存され、セッションIDはブラウザに保存される。
ブラウザがサーバーにリクエストする時、セッションIDを渡す→サーバーがIDに対応したデータを返す。 - Cookieでユーザーの判別が行われ、セッションによってそのユーザーがとった行動と結びつけられることで、「通販サイトのカート内商品の保持」といった機能が実現される。
Cookieの問題点
- Cookieは便利だが、プライバシー面・セキュリティ面において注意しておくべき点もある。
- Tracking Cookie(トラッキングクッキー)
- セッションハイジャック
Cookieの識別子が漏えいする:右矢印:CookieにはサイトのセッションIDとともに、ログイン情報が含まれていることがある:右矢印:情報自体がSSLなどで暗号化されていても、セッションIDさえわかってしまえばサーバーに送ることで、ログイン状態が再現されてしまう。
考えたこと
- HTTPが登場したのは1990年代らしい。私が生まれたのが1995年なので、想像していたよりも最近で驚いた。
- HTTPの進化に感動した。私が小学生の時に父が使っていたPCは、Webページを表示するのにとても時間がかかり、画像も少しずつジワジワと読み込んで表示されていた。今はそんなことは有り得ず、wifiなどのネット回線に問題がなければ、たくさん画像が使われたWebページでも一瞬で表示できる。今ネットを便利に使えているのは、HTTPの進化のおかげなのだな、と思った。
- HTTPのバージョンを知る方法を調べた。
デベロッパーツールを開き、networkタブのProtocolを見ると、バージョンが分かる。

ch4. Webのさまざまなデータ形式
学んだこと
スクリプト言語
- サーバーサイド・スクリプト(Ruby)はwebサーバーのCGIが呼び出すプログラム。
- クライアントサイド・スクリプト(JavaScript)は「webブラウザによって」読み込まれるプログラム。
→裏側の処理と見た目の処理で、読み込む人が違う。
フィード
- webサイトなどの更新履歴を配信するためのファイル。中身はハイパーリンクの集まり。
- ブログやニュースサイトで使われる
- webサイトにアクセスすることなく、最新情報をチェックできる
フィードリーダー
- フィードを取得&管理するためのソフトウェア
- お気に入りのwebサイトを登録しておくことで、わざわざそのサイトにアクセスしなくても最新情報や更新情報をチェックできる便利な情報収集ツール
- ウェブサイトの見出しや要約、更新情報を記述したフィードを巡回・受信し、一覧表示するソフトウエア。RSS形式のフィードを扱うRSSリーダーを指すことが多い。
= RSSリーダー
フィードリーダーは現在は衰退している
- フィード/フィードリーダーを初めて知ったので、調べてみたら、現在は衰退しているようだった。
- 2013年にGoogleのRSSリーダーが、おそらくユーザー減少を理由に、サービスを終了している。
- 現在は、SafariもGoogleもFirefoxもRSSリーダーを実装していない
- 衰退した原因は、SNSやキュレーションアプリの普及と思われる。たしかに、最新の情報を収集したいと思ったら、SNSやキュレーションアプリの方が便利だと思った。
YouTubeやニコニコはストリーミング配信ではないのか
- 本では、
と説明されていたが、ストリーミング配信ではないのかと疑問に思ったため、調べた。
3つの配信方法の特徴・違い
- 音声・動画の配信方法は3つある。
- ダウンロード配信
- ダウンロードを全部完了するまで再生できないが、完了すればいつでも再生できる
- 例:Amazonプライムの動画をDLした時、途中までしかできていないと視聴することができない。
- プログレッシブダウンロード配信
- ダウンロードしながら再生
- 疑似ストリーミング
- 配信したファイルはユーザー側に残る
- ストリーミング配信
→YouTubeを視聴する時に、見たい動画のURLや配信ページにブラウザで接続した時にしか視聴できないので、「いつでも再生できる」という説明が理解できなかった。ストリーミング配信ではないのか?
YouTubeを調べてみた
YouTubeで動画を見ると、映像の下に赤いラインとグレーのラインがある。赤いラインは再生した部分を示し、グレーの部分はダウンロードした部分を示している。 →このグレーの部分は、ダウンロードしている部分だった。

濃いグレーの部分は、まだダウンロードが完了していない部分。ダウンロード配信では、全部ダウンロードが完了していないと、視聴することができないので、YouTubeはダウンロード配信ではない。
- よって、YouTubeやニコニコ動画は、プログレッシブダウンロード配信であることが分かった。
- プログレッシブダウンロード配信も動画データが一時的に端末へ保存されているので、目に見えづらかっただけで、YouTubeを視聴している時に、一時的にスマホやPCに動画が保存されていることが分かった。
考えたこと
- このチャプターでは、webで使われている様々なデータ形式について学んだ。学習でさわったことのあるHTMLやCSSについてはすんなり理解できたが、この本で初めて知ったJSON,DOM,マイクロフォーマット,フィードなどは、触ったことがないので、読んでもイメージしづらかった。実際に学習や仕事でさわることになった時に、また読んで理解を深めたい。
- 自分が使っていたAmazonプライム,Netfrix,YouTubeなどの動画配信サービスの配信方法が何かについて、考えるのが面白かった。
ch5. Webアプリケーションの基本
学んだこと
Webクライアント
- Webクライアント = Webブラウザのみを指すと勘違いしていたので、調べて整理した。
- Webクライアントとは
クライアントプログラム
- Webブラウザは多くのwebアプリケーションに対する凡庸的なwebクライアントだが、webブラウザでは利用できないものや、十分に機能を活かせないものについては専用のクライアントプログラムが用意される。
- クライアントプログラムは、パソコン用であればデスクトップアプリ、スマートフォン用であればスマホアプリと呼ばれることもある。
- デスクトップアプリ:コンピュータにインストールして利用するアプリケーションソフトウェア
- Twitterに例えて考えてみた
CDN
CDNが何か、本の説明だけでは理解できなかったので、調べたことを整理した。
インターネットの世界にも現実世界と同じように「距離」の概念がある
- 自分の使っているwebブラウザと相手のwebサーバーの距離が近ければ、それだけwebページを早く見られる。
- 世界各地にwebサーバーを設置し、大元のwebサーバーからwebページのファイルをコピーしておく(お互い連携している=1つのネットワーク)
- これによって、ホームページを見る人は、自分の近くにあるWebサーバからホームページのファイルを受け取れる。
- このwebサーバーが集まったネットワーク(世界各地に分散されたキャッシュサーバーの集合体)をCDNという!
Ajax
- 同期通信には、「リクエストを送ってレスポンスがかえってくるまで、クライアントは待つことしかできない」という欠点がある。
- Ajaxという技術では、JavaScriptがクライアントとして直接webサーバーと通信をする。必要なデータだけやり取りするため、同期通信よりもサーバーへの負担が少なく済む。
- JavaScriptのおかげで非同期通信が可能。
- レスポンスを待つ間も、レスポンスに左右されない箇所のHTMLを更新したり、ユーザーからの入力を受け付けられたりするなど、レスポンス待ちの時間を有効活用できる→ページの更新が早くなる。
Googleマップの地図の表示部分で使われている
具体的にAjaxがどのように使われているか疑問に思ったので、調べた。
Googleマップ地図をスライドすると、その先の地図が表示される。
- これは、スライドしている間に足りない地図のデータをAjaxでリクエストしているから、ぬるぬると地図を動かすことができる。
- 1回目の通信はリクエスト⇔レスポンス(同期処理)で行い、2回目からはAjaxという技術をつかって、JavaScriptに必要なデータ分だけを取ってきてもらう、という流れ。
- もしAjaxがなければ、スライドする度にページを再読み込みする必要がある。
Web API
- 本では、
- ユーザーではなくプログラムが直接サービスを利用できるための窓口
- アプリケーションがWebサーバーの機能を利用するためのインターフェース(接点)
と説明されていたが、意味が理解できなかったので、実際にWebAPIが使われているサービスを見て調べた。
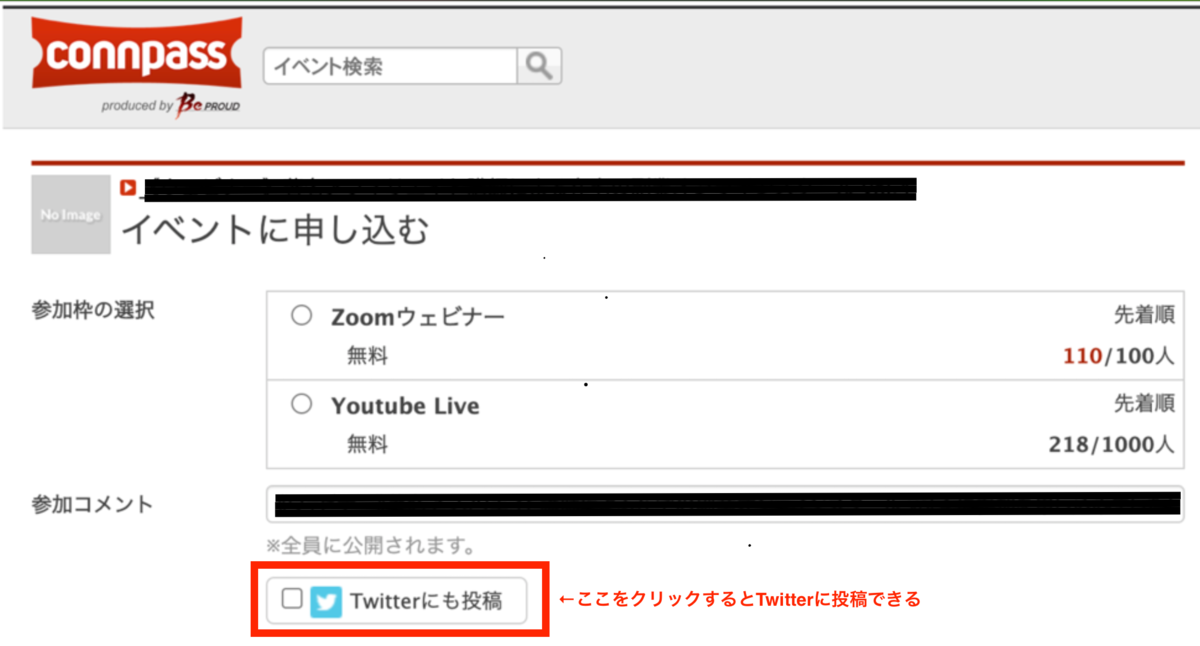
- これは、コンパスがTwitterが提供している「ツイートする」WebAPIを利用しているため、ユーザーの代わりに事前にTwitterのWebサーバー(が提供してるWebAPI)からデータを取得することで、実現できている。
- ユーザーはこれのおかげで、わざわざTwitterというWebサービスに自分で接続しなくても、connpassというWebサービス内から参加コメントをツイートすることができる。
= 本の「ユーザーがWebブラウザから操作しなくても、アプリケーションが直接Webサービスを利用できます」という説明は、このことを言っている。
考えたこと
- Googleマップを快適に使えているのはAjaxのおかげだったとは知らなかった。地図を移動する度に、ページを再読み込みしていたら非常に使いづらいと思うので、感謝。
- 新しいことを学んだ時に、イメージが湧かない時は、実際のWebサービスのどの機能に当たるか、どこに使われている技術かを調べることで、理解を深められた。
ch6. Webのセキュリティと認証
学んだこと
- すべての驚異や脆弱性への対策をするのは難しいので、一般的にはリスクによる損失の度合いを算出し、それに応じて優先順位を決めた上で対策する。
ファイアーウォールはどこに設置するのか
- ファイアーウォールとは:企業などの内部ネットワークをインターネットを通して侵入してくる不正なアクセスから守るための防火壁。
本の説明で、ファイアーウォールがシステムのどこに設置されているのか分からなかったので、調べた。
外部ネットワークとDMZ、DMZと内部ネットワーク、それぞれの間にファイアウォールが入るような構造を作り、通信を仕分ける。
- DMZとは
- 外部ネットワークと社内ネットワークの中間につくられるネットワーク上の区域
- 外部ネットワークからも内部ネットワークからもファイアウォールなどによって隔離されている。
- 外部に公開することが前提となるWebサーバは、常にリスクに晒されている。もし、Webサーバーを社内ネットワーク(=内部ねっと)に置くと万が一乗っ取られたり(リモートハッキング)、悪意のあるマルウェアなどを組み込まれたりした場合、社内ネットワークに接続されているその他のサーバやパソコンがすべて被害を受ける可能性がある。
- 何のためにあるのか?→危険な地域のすぐそばに大切なものを置いておくのは危ないので、何かトラブルが起きても大丈夫なように緩衝地帯を設けて、そこに大切なものを置かないようにするためにある。
- ファイアウォールはDMZを置かない状態でも設置できるが、Webサーバと外部ネットワークの間に設置されるファイアウォールは広く開放されている状態で、警戒が緩く、外部からの攻撃に対して脆弱な状態。Webサーバが内部ネットワークに置かれていると、乗っ取られたWebサーバを踏み台にして内部ネットワークも簡単に攻撃を受けてしまうので、DMZが必要。

考えたこと
- 自分が被害を受けたことがないのもあって、セキュリティについて深く考えたことがなかったが、ドコモ口座の不正アクセスなど、かなり身近な問題。
- これから消費者側ではなくサービスを開発して提供する側を目指すので、きちんと学んでセキュリティ面も考えて開発ができるエンジニアにならねばと思った。
- 個人情報の漏洩がどれくらいの頻度で起こっているか気になったので調べたら、知らないだけで意外と結構あった。自分の個人情報も気づいてないだけで結構抜かれているのではと怖くなった。
ch7. Webシステムの構築と運用
考えたこと
- アプリケーション設計は、機能の一覧、アプリケーションの構成図、画面レイアウトなど表面的な部分の設計らしい。
エンジニアとして就職したら、おそらく全部を自分でやるのでなく、- サーバーやセキュリティなどインフラをどうするかはインフラエンジニア
- 機能の洗い出しなどはRubyを書いたりDB設計をするサーバーサイドエンジニア
- 画面のデザインはWebデザイナー、マークアップエンジニア、フロントエンドエンジニア
が主に決めたり各々同士が話し合ったりして設計ができるのだろうか。 これら全部を一人でする経験ができる、自作Webアプリ開発のカリキュラムが楽しみだと思った。
- バックアップ運用について調べていたら、恐ろしいニュースを見つけた。
福井県の中小企業支援サイトで全データ消失 - クラウド契約先が手続ミス
この事件はプログラムに問題があったわけではなく、伝達ミスによるもののようだが、気をつけないとこういう事態もあり得るのだな、と教訓になった。
全体の感想
- この本はTECHPLAY女子部の方と2人で輪読会を行って読み進めた。
輪読会についての感想は以下にまとめてある。
- 一つ一つの用語を見開き1ページに丁寧に解説をしてくれており、ページの半分は図で解説してくれているので、初心者の私にとってとても読みやすかった。 Webを支える技術で分からない用語があった時に、この本を辞書代わりにして読むと良さそうだと思った。